近日,一篇由澳洲悉尼大学团队牵头完成的论文在 X 上引起关注,该校的博士生孙艺菲(Yifei Sun,音)是论文第一作者。
基于人类连接组计划的功能性磁共振成像数据,他们使用 Transformer 预测了人脑静息状态(human brain resting states)(注:人类连接组计划是美国国立卫生研究院于 2009 年开始资助的一个 5 年项目,由几所研究机构分成两组进行)。
具体来说,他们提出一种基于时间序列的 Transformer 架构,在功能性磁共振成像采集中观察到的一系列先前时间点的情况下,成功预测了大脑 379 个灰质区域的大脑状态,单时间点预测均方误差为 0.0013。
研究中,他们将大脑状态预测问题构建为一个自回归任务,在给定序列的情况下来预测下一个时间元素。
借此发现,该模型可以准确预测大脑的即时状态,其中预测 5.04 秒的大脑状态误差较小,预测 10 分钟以上的大脑状态与人类功能连接组的平均值一致(注:功能连接,是指大脑不同脑区之间在功能上的相互关联和影响,主要通过分析不同脑区记录的信号来计算反映不同脑区关系强弱的某种指标)。
本次方法也能学习大脑状态随时间的时间依赖性,基于 21.6s 的功能性磁共振成像数据可以准确预测约 5.04s 的状态。
此外,即使预测误差随着时间的推移而累积,所生成的功能性磁共振成像大脑状态,也能反映功能连接的结构。另据悉,本次研究的相关代码已开源(https://github.com/syf0122/brain_state_pred)。

基于自注意力机制力的架构,能充当大脑未来状态的“预言师”
人脑是一个复杂的动态系统,有数百亿个神经元和数万亿个突触连接。了解人脑的动态机制始终是神经科学领域的首要任务,因为它对于揭示认知、情感、语言和其他更高层次人类智能的起源至关重要。
此外,这种理解对于破译阿尔茨海默病和精神分裂症等脑部疾病背后的机制至关重要。同时,脑机接口(BCI,brain-computer interfaces)和大脑启发的 AI 技术正在发展成为当前的技术趋势,因此学习大脑机制是模仿人脑的重要一步。
功能性磁共振成像是一种广为使用的非侵入性技术,它能在中观尺度上观察整个大脑的空间动态,以及在第二尺度上观察时间动态。
尽管人们在绘制大脑功能组织方面取得了重大进展,例如用静息态脑功能磁共振成像重建了内在网络。但是,大脑的功能连接——是了解大脑健康和心理健康的重要生物标志物。
而当大脑没有执行特定任务时(即静息状态),大脑活动到底是如何出现?对于这一问题仍然没有得到解答。此外,从静息状态获取的具体序列脑状态是否可以预测?这仍然是一个未知数。
而假如能够解决这一问题,则有望缩短有困难患者或残疾患者的功能性磁共振成像扫描时间。如果可以预测大脑状态,那么某些致命性脑部疾病(如癫痫)的疼痛和伤害也可以避免或减少。
同时,预测大脑状态可以为脑机接口技术铺平道路,有望让该技术实现更直观、更有效的沟通。
自从相关研究人员于 2017 年引入多头自注意力(Multi-headed?Self-attention)以来,Transformer 架构在深度学习中可谓无处不在,并主要专注于处理序列任务和图像多任务。
ChatGPT 便是其中一个成功案例,它展示了
Transformer 在处理自然语言顺序信息上的强大功能。Transformer 能从知识库中学习模式,并能在连续对话的背景下给出答案。
鉴于它们能够找到基于相关性和与图论联系的数据 tokens 之间的远距离关系,本次研究团队认为基于自注意力机制力的架构,能够从连续的大脑活动中预测即将到来的大脑状态。
最近,有研究人员证明 Transformer 架构在分析功能性磁共振成像数据具备年龄预测、性别分类和疾病分类方面的潜力。
此外,脑语言模型(BrainLM,brain language model)是一种能够监测大脑动态活动的基础模型。在使用脑语言模型的时候,需要经过预先训练以便进行掩蔽预测,然后针对大脑状态预测进行微调。
然而,脑语言模型需要使用大型数据集进行预训练,而大脑状态预测需要相对较长的时间序列(180 个时间点)。
因此,假如训练一个能够根据更短的输入时间序列来预测大脑状态的模型,就可以大大缩短功能性磁共振成像的扫描时间。

采用 1003 名健康年轻人的 3.0T 功能性磁共振成像数据
基于此,研究人员使用了人类连接组计划的年轻人数据集的静息状态功能性磁共振成像数据。他们采用 1003 名健康年轻人的 3.0T 功能性磁共振成像数据,并排除了其中 110 名成像缺失或不完整的受试者。
这些受试者都曾使用四次功能性磁共振成像扫描,每次扫描 1200 个时间点,并采用存储基于表面的灰质数据的 CIFTI 格式(注:CIFTI 的英文全称是 Connectome Imaging Format for Tomography,它是一种用于存储和表示大脑连接组数据的文件格式)。
人类连接组计划的功能性磁共振成像数据具有 2mm 的各向同性空间分辨率和 0.72s 的时间分辨率。
除了人类连接组计划数据集已能提供的最小预处理之外,该团队还进行了几个额外的预处理步骤,以便进一步地清理数据,并为训练和测试 Transformer 准备数据。
研究中,他们使用高斯滤波器对功能性磁共振成像数据进行空间平滑处理,高斯滤波器在 CIFTI 格式中将半峰全宽设置为 6mm,以便降低噪声和提高信噪比(注:半峰全宽,是指在色谱分析中色谱峰高一半处的峰宽度)。
然后,他们采用带通滤波器滤除一些不感兴趣的噪声,同时将时间信号保持在 0.01Hz 至 0.1Hz 的范围内。
为了将所有样本放在一个共同尺度上,他们针对时间序列进行 z 分数变换,以便获得零时间均值和单位标准差(注:z 分数,是一个数与平均数的差再除以标准差的过程)。
接着,他们使用多模态分割图谱,计算了 379 个大脑区域的平均功能性磁共振成像时间序列,其中包括 360 个皮质区域和 19 个皮质下区域。基于此,他们使用每个时间点信号强度为 379 个区域的向量来表示大脑状态。
人脑是一个动态系统,它的当前状态与之前状态有关。因此,研究人员也探索了这样一个问题:在给定一系列先前大脑状态的情况下,是否可以预测单个大脑状态?为了模拟这些预测,他们重新设计一个为流感预测(influenza forecasting)开发的现有时间序列 Transformer 模型。该模型由 Transformer 编码器和 Transformer 解码器组合而来。
在使用时,Transformer 将由具有给定窗口大小的 token 序列表示的时间序列数据作为输入。由于自注意力机制会将标记关系视为一个图,因此可以使用正弦函数和余弦函数的位置编码,来添加相对的时间信息。
网络的编码器,包含四个具有自关注和前馈的编码层。编码层,则包含八个注意头。最终,这一编码堆栈可以生成编码器输出。
研究人员把编码器输入的最后一个时间点与编码器输出加以结合,以此作为解码器的输入,这时解码器会被定义为四个解码层的堆栈,而这些解码层也由自注意力机制和前馈层组成。
随后,全连接层会将解码器层堆栈的输出映射到目标输出形状。与流感流行病例的时间序列 Transformer 不同,该团队的模型能够预测一系列的未来时间点,并能通过采用前瞻性掩蔽来预测基于过去的数据。

生成 1150 个时间点的合成时间序列的预测结果
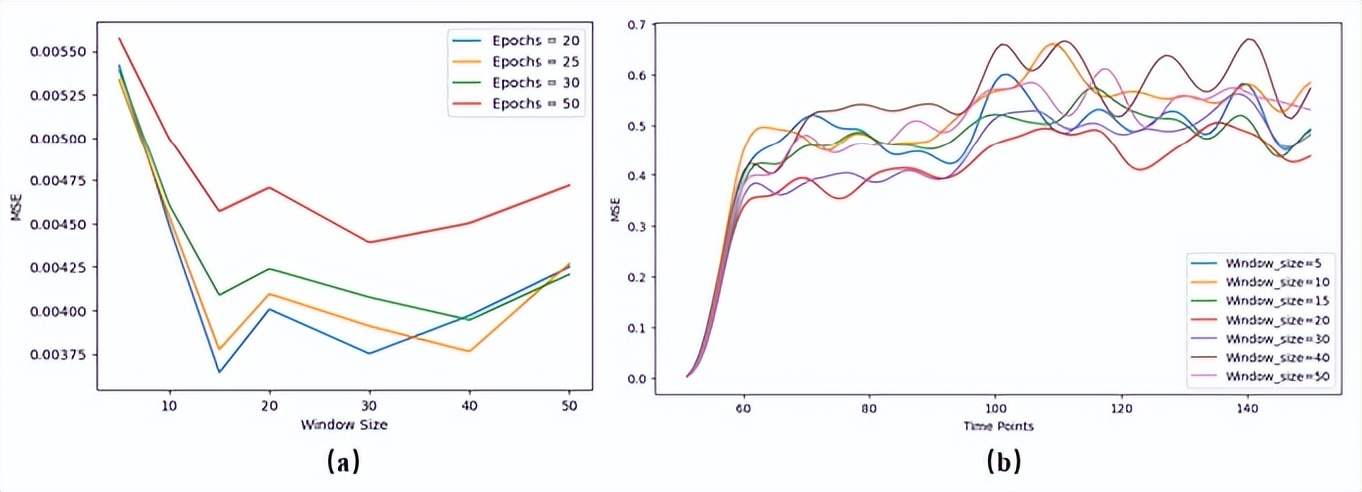
当将大脑状态预测问题定义为自回归任务时,研究人员使用均方误差(MSE,mean squared error)作为损失函数。他们首先针对 40 名受试者的数据进行不同窗口大小的初步测试。
具体来说,他们输入了时间序列之间的重叠,因此每个功能性磁共振成像会话数据能够产生 1150 个训练样本。
训练期间,研究人员从所有受试者和所有会话的训练数据中随机选择样本。训练完毕 Transformer 网络之后,研究人员使用模型此前没有见过的受试者的功能性磁共振成像数据评估其性能。
首先,他们测试了该模型从真实功能性磁共振成像数据中预测单个大脑状态的能力。然后,他们使用相同的输入序列进行类似测试,其中大脑状态的顺序是随机的。
研究人员假设:当以随机序列输入相同的数据时,一个能够学习顺序信息和大脑动力学的模型应该会产生更高的误差。
为了验证这一假设,他们针对两种测试的均方误差进行比较,并对两组均方误差结果进行了配对 t 检验(paired t-test)(注:配对 t 检验是配对样本 t 检验的简称,用于检验相关或相互依赖的配对观测值之间的平均差是否存在显著差异)。
之后,他们评估了模型的这一能力,即采用有限的真实功能性磁共振成像数据和不断增加的合成状态,来预测一系列大脑状态的能力。
具体来说,他们使用 30 个真实的功能性磁共振成像时间点来预测下一个时间点,然后将该预测与真实时间序列连接起来,并将输入窗口移动一步,以迭代的方式囊括新的预测时间点,直到合成与真实数据(1200 个时间点)长度相同的时间序列序列。
通过此,研究人员生成 1150 个时间点的合成时间序列的预测结果,并计算了预测时间序列和真实功能性磁共振成像数据之间的均方误差,以及每个预测和真实大脑状态之间的斯皮尔曼相关系数,以便可以测试单调相关性(monotonic correlations)(注:斯皮尔曼相关系数,是一种非参数统计方法,用于评估两个变量之间的单调关系,而非用于评估线性关系)。
同时,研究人员使用区域时间序列之间的皮尔逊相关系数,计算了真实功能性磁共振成像时间序列和预测功能性磁共振成像时间序列的功能连接矩阵(注:皮尔逊相关系数,是一种统计度量,用于量化两个变量之间的线性关系强度和方向)。至此,本次研究正式进入尾声。
未来,研究人员希望通过减轻误差累积问题来改进这种 Transformer 架构,以便生成更准确的预测,这将有助于研究那些长期无法进行功能性磁共振成像扫描的人群的大脑功能。
同时,研究人员还计划通过使用迁移学习(transfer learning)来开发个性化模型。此外,研究人员此次提出的方法还具有一定的可解释性,因此也能用于探索人脑的功能原理。
